名寄せとは?手順や効率化ツール、注意点をわかりやすく解説
- INDEX
-

名寄せとは、複数のデータベースに散在する顧客情報を一つに統合し、整理する作業のことです。
この記事では、名寄せの基本的な意味から、具体的な手順、効率化に役立つツール、実施する上での注意点までを網羅的に解説します。
データ管理の精度を高め、ビジネス成果を最大化するための第一歩として、正確な知識を身につけましょう。
そもそも「名寄せ」とは?初心者にも分かりやすく解説
名寄せとは、元々、金融機関が同一人物の口座を一つにまとめるために使っていた言葉です。
現在では、ビジネス全般において、複数のリストやデータベースに重複して登録されている同一の顧客のデータを特定し、一つに統合・整理する作業全般を指す意味で使われます。
保険や年金の分野でも同様の考え方が用いられます。
英語ではデータ重複排除やと表現されることが多いです。
この作業は、正確な顧客データを維持するための基本となる重要な定義の一つです。
顧客データを一つに統合するデータ整理のこと
ビジネスにおける名寄せは、企業が保有する様々な形式の顧客データの中から、同一人物や同一企業を特定し、関連する情報を集約して一つのマスターデータを作成する作業を指します。
例えば、営業部門の顧客リスト、マーケティング部門のメール配信リスト、カスタマーサポートの問い合わせ履歴など、部署ごとに管理されているデータの重複を解消し、一元化することが目的です。
これにより、企業は顧客一人ひとりに対して統一されたアプローチが可能になります。
名寄せとデータクレンジングの具体的な違い
名寄せとデータクレンジングは混同されがちですが、目的と作業内容が異なります。
データクレンジングは、データの「質」を高める作業です。
具体的には、誤字脱字の修正、古い情報の更新、住所や電話番号の形式統一などを行い、データを正確で最新の状態に整えます。
一方、名寄せは、クレンジングされたデータをもとに「重複」しているデータを特定し、一つに統合する作業を指します。
つまり、データクレンジングは名寄せを行うための前処理として位置づけられることが多いです。
| 項目 | データクレンジング | 名寄せ |
|---|---|---|
| 目的 | データの「質」を高める | データの「重複」を解消し一つに統合する |
| 主な作業 | 誤字脱字の修正、古い情報の更新、住所や電話番号の形式統一 | 重複しているデータを特定し、一つのマスターデータに集約する |
| 作業の順序 | 名寄せを行うための前処理として位置づけられる | クレンジングされたデータをもとに実施する |
| 関係性 | データクレンジング(前処理)→ 名寄せ(統合)の順で実施する | |
関連記事:名刺をデータ化する目的と最適な手法
なぜ今、名寄せがビジネスで重要視されるのか
現代のビジネスにおいて、データは企業の重要な資産です。
しかし、データが様々な場所に散在し、重複や表記ゆれが存在すると、その価値を十分に活かすことができません。
名寄せは、こうしたデータの乱立を整理し、データに基づいた正確な意思決定や効率的な事業活動を可能にする目的で重要視されています。
顧客理解を深め、競争優位性を確立するための基盤作りとして、その必要性はますます高まっています。
顧客情報の正確性を維持し最新の状態に保つため
顧客の情報は、部署移動や転職、企業の移転などで常に変化します。
古い情報や誤ったデータが残っていると、DMの不達や重要な連絡の行き違いなど、機会損失や信用の低下につながりかねません。
名寄せを定期的に実施することで、顧客データを正確かつ最新の状態に保ち、リアルタイムな変化に対応できる体制を整えることが可能です。
これにより、顧客との良好な関係を維持しやすくなります。
複数のシステムに散在したデータを一元管理するため
多くの企業では、SFA(営業支援システム)、MA(マーケティングオートメーション)、CRM(顧客関係管理)など、部署ごとに異なる目的で複数のシステムを導入しています。
その結果、同じ顧客の情報がそれぞれのシステムに別々に登録され、データが分断される「サイロ化」という問題が発生しがちです。
名寄せによってこれらのデータを統合し一元管理することで、全社で統一された顧客情報を共有し、部門間の連携をスムーズにします。
営業やマーケティング活動の成果を最大化するため
データが重複していると、同じ顧客に複数の営業担当者がアプローチしたり、同じ内容のメールを何度も送ったりといった非効率な活動が発生します。
特に法人営業では、企業名や部署名の表記ゆれによって同一企業を別会社として扱ってしまうミスも起こりがちです。
名寄せによってデータを整理することで、顧客一人ひとりや一社ごとの状況を正確に把握し、パーソナライズされた最適なアプローチが実現でき、活動の成果を最大化できます。
関連記事:CRMとは?基本の意味からSFA・MAとの違い、導入メリット・活用方法まで徹底解説
名寄せを実施することで得られる3つのメリット
名寄せは、単にデータをきれいにするだけでなく、企業経営に多くのメリットをもたらします。
データ管理の効率化によるコスト削減、正確なデータに基づく戦略立案、そして顧客へのアプローチ精度向上による信頼関係の構築が主な利点として挙げられます。
これらのメリットは相互に関連し合い、企業の競争力強化に直接的に貢献します。
| No. | メリット | ポイント |
|---|---|---|
| ① | データ管理の工数が削減されコストカットにつながる | データ一元化で情報を探す時間や手作業の修正工数が削減される。DMの二重発送にかかる郵送費・印刷費のコストカットにもつながる |
| ② | 正確なデータに基づいた経営戦略を立てられる | 重複データ解消で正確な顧客数を把握でき、市場分析・売上予測の精度が向上する。データドリブンな意思決定を支援する |
| ③ | 顧客へのアプローチ精度が向上し信頼関係を構築できる | 取引履歴・問い合わせ内容・マーケティング反応を統合的に把握でき、きめ細やかな対応が可能になる。二重アプローチなどのミスを防ぎ顧客満足度を高める |
データ管理の工数が削減されコストカットにつながる
データが重複・散在している状態では、必要な情報を探し出すのに時間がかかったり、手作業でのデータ修正に多くの人件費を要したりします。
名寄せによってデータが一元化されれば、こうした無駄な作業が大幅に削減されます。
また、DMの二重発送にかかる郵送費や印刷費などのコストも削減できるため、業務効率化と経費削減の両方を実現できます。
正確なデータに基づいた経営戦略を立てられる
重複したデータが存在すると、実際の顧客数を過大に評価してしまい、市場分析や売上予測に誤りが生じる可能性があります。
名寄せによって正確な顧客数を把握することで、データ分析の精度が向上します。
信頼性の高いデータに基づいて顧客の購買傾向やニーズを分析できるため、より的な経営戦略や事業計画の立案が可能となり、データドリブンな意思決定を支援します。
顧客へのアプローチ精度が向上し信頼関係を構築できる
顧客情報が一元管理されることで、過去の取引履歴や問い合わせ内容、マーケティング活動への反応などを統合的に把握できます。
これにより、顧客一人ひとりの状況に合わせたきめ細やかな対応が可能になります。
例えば、既に契約済みの顧客に新規開拓の営業電話をかけてしまうといったミスを防ぎ、顧客満足度を高めることで、長期的な信頼関係の構築につながります。
放置は危険!名寄せをしない場合に起こりうる問題点
顧客データの重複や散在を放置することは、多くの経営リスクを内包しています。
同じ顧客への二重アプローチによる信用の失墜、非効率な営業活動によるコストの増大、不正確なデータ分析に基づく戦略ミスなど、事業活動の根幹を揺るがしかねない問題に発展する可能性があります。
これらのリスクを回避するためにも、名寄せによるデータ管理体制の構築は不可欠であり、放置することは非常に難しい課題です。
顧客への二重アプローチで信頼を損なう
異なる部署の担当者が、同じ顧客に対して別々に営業アプローチをしてしまうケースは、名寄せができていない企業で頻繁に起こる問題です。
顧客にとっては「社内の情報共有はどうなっているのか」という不信感につながります。
また、メールマガジンの配信停止を依頼したにもかかわらず、別のリストから送信され続けるといった情報の引き継ぎ漏れも発生しやすく、顧客満足度を大きく損なう原因となります。
非効率な営業活動で無駄なコストが増える
重複した顧客リストに基づいて営業活動を行うと、時間や費用といったリソースを無駄に消費してしまいます。
例えば、同じ企業に複数の担当者が電話をかけたり、同じ内容のダイレクトメールを複数送付したりすることは、人件費や通信費、郵送費の無駄遣いです。
こうした非効率な活動は、営業担当者のモチベーション低下を招くと同時に、企業の収益性を圧迫する要因にもなります。
不正確なデータ分析で戦略を誤る
データが重複していると、顧客数やセグメントごとの分布を正しく把握することができません。
例えば、実際の顧客数が100人なのに、データ上では150人として集計されてしまうと、市場規模や成長性を過大評価し、誤った経営判断を下すリスクが高まります。
不正確なデータに基づく需要予測や販売戦略は、過剰な在庫や機会損失を招き、事業全体に深刻な影響を及ぼす可能性があります。
初めてでも分かる!名寄せの具体的な4ステップ
名寄せを行う際は、計画的に作業を進めることが重要です。
やみくもにデータを統合しようとすると、かえって混乱を招く可能性があります。
ここでは、基本的な名寄せのプロセスを4つのステップに分けて解説します。
この手順に沿って作業をすることで、効率的かつ正確にデータの統合を進めることができます。
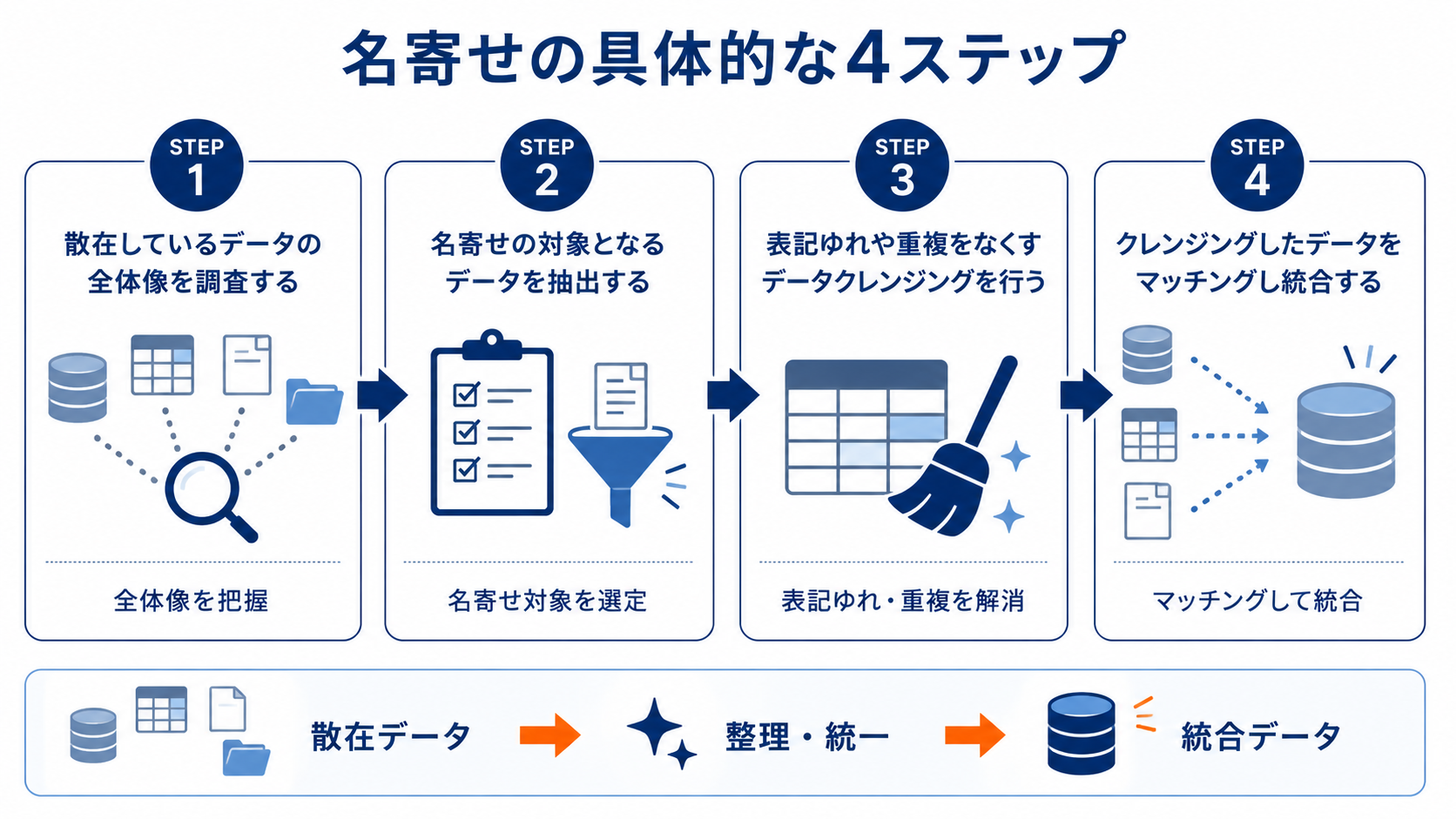
STEP1:散在しているデータの全体像を調査する
最初に、社内のどこに、どのような顧客データが存在するのかを全て洗い出します。
営業担当者が個別に管理しているExcelのリスト、過去のイベントで集めた名刺データ、SFAやMAツール内の顧客情報など、考えられる全てのデータソースが調査対象です。
それぞれのデータがどのような項目(氏名、会社名、住所など)を持ち、どの程度の件数があるのか、元のデータの全体像を把握することが最初のステップです。
STEP2:名寄せの対象となるデータを抽出する
社内に存在する膨大な情報から、統合の対象とする範囲を明確に定めます。すべてのデータを一度に処理するのは現実的ではないため、優先順位をつけて進めることが重要です。
まずは利用頻度の高いメインシステムや、最新の顧客情報が含まれるデータベースを中心に抽出対象を選定します。対象が決まったら、各システムから必要な項目を取り出し、作業用の環境へ集約します。
この際、後の工程で照合がスムーズに行えるよう、最低限のフォーマットを意識してデータを整理することがポイントです。抽出作業を丁寧に行うことで、名寄せ全体の精度と効率が大きく左右されます。この工程を名寄せの進め方における土台として捉え、正確に進めましょう。
STEP3:表記ゆれや重複をなくすデータクレンジングを行う
抽出したデータに対して、表記の統一や誤りの修正といったデータクレンジングを実施します。
具体的には、「(株)」と「株式会社」の統一、全角・半角の統一、不要なスペースの削除などを行います。
また、郵便番号と住所の整合性を確認したり、古い住所の情報を更新したりする作業も含まれます。
特に企業データでは社名の表記、個人データでは住所の建物名や世帯情報まで、細かな表記ゆれをなくすことが重要です。
STEP4:クレンジングしたデータをマッチングし統合する
データクレンジングの後、いよいよデータの統合であるマッチング作業に入ります。氏名、会社名、住所、電話番号、メールアドレスといった複数の項目をキーとして照合し、同一人物または同一企業と判断されるデータを特定します。
特定された重複データは、一方を正とし、もう一方の情報を補完する形で統合します。この作業を経て、最終的に重複のない正確なマスターデータが完成します。金融機関における複数口座の統合と同様の考え方で、一つの顧客IDに情報を集約していきます。
大量のデータを扱う際や、より高い精度を求める場合には、自動でマッチングを行うツールの活用が効率的です。手作業によるミスを防ぎながら、迅速に情報の集約を進めることができます。
名寄せを効率化するための主な方法
名寄せの作業は、データ量が多くなるほど手作業での対応が困難になります。
そのため、企業の規模やデータの状況に応じて、適切な方法を選択することが重要です。
ここでは、手動で行う基本的な方法から、ツールを導入して自動化する方法まで、主な効率化の手法を紹介します。
Excelやスプレッドシートを使って手動で行う方法
データ量が比較的少ない場合、ExcelやGoogleスプレッドシートの機能を活用して手動で名寄せを行うことができます。
具体的には、「VLOOKUP」や「COUNTIF」といった関数を使って重複データを検出したり、ソート機能やフィルタ機能で表記ゆれを見つけやすくしたりする方法です。
エクセルやスプレッドシートは多くの企業で導入されているため手軽に始められますが、作業に時間と手間がかかり、人的ミスも発生しやすいというデメリットがあります。
SFA/CRMや専用ツールを導入して自動化する方法
大量のデータを高精度かつ効率的に処理したい場合は、ツールの導入が有効です。
多くのSFA/CRMには、標準で名寄せ機能が搭載されており、新規データ入力時に重複を自動でチェックしてくれます。
また、名寄せに特化した専用ツールも存在します。
これらのツールは、独自のアルゴリズムを用いて、単純な文字列一致だけでなく、類似した表記も同一データとして判定することが可能です。
法人向け名刺管理サービスのホットプロファイルやSansanなども、高精度な名寄せ機能を提供しています。
名寄せを成功させるために押さえておきたい注意点
名寄せは、一度実施して終わりではありません。
データの品質を継続的に維持し、その価値を最大限に引き出すためには、いくつかの重要なポイントを押さえておく必要があります。
ここでは、名寄せを成功に導き、その効果を持続させるための注意点を3つ解説します。
個人情報の取り扱いはプライバシーポリシーに準拠する
名寄せの対象となる顧客データには、氏名や連絡先といった個人情報が多数含まれます。
これらの情報を取り扱う際は、個人情報保護法をはじめとする関連法令を遵守することはもちろん、自社で定めたプライバシーポリシーに従う必要があります。
データの統合や利用目的がポリシーの範囲内であるかを確認し、セキュリティ対策を徹底するなど、慎重な対応が求められます。
データの重複を防ぐための入力ルールを策定する
せっかく名寄せを行っても、その後に登録されるデータがバラバラでは、再び重複や表記ゆれが発生してしまいます。
これを防ぐためには、全社共通のデータ入力ルールを策定し、運用を徹底することが不可欠です。
例えば、「会社名は必ず登記上の正式名称で入力する」「(株)は使わず『株式会社』に統一する」といった具体的なルールを定めます。
事業内容の変更などに伴い、定期的にルールを見直すことも重要です。
定期的なメンテナンスでデータの鮮度を保つ
顧客データは、企業の移転や合併、担当者の異動・退職など、時間の経過とともに常に変化し、古くなっていきます。
そのため、データの品質を維持するためには、定期的なメンテナンスが欠かせません。
四半期に一度、半年に一度など、自社の状況に合わせてスケジュールを決め、データクレンジングや名寄せを継続的に実施する体制を整えることが、データの鮮度を保つ上で重要です。
名寄せに関するよくある質問
ここでは、名寄せに関して頻繁に寄せられる質問とその回答をまとめました。
作業期間や外注の可否、実施のタイミングなど、具体的な検討を進める上での参考にしてください。
名寄せの作業にかかる期間はどれくらいですか?
名寄せにかかる期間は、対象となるデータの量や質、作業方法によって大きく異なります。
数万件程度のデータであれば、手動でも数週間から1ヶ月程度が目安です。
しかし、データが数十万件を超える場合や、複数のシステムに散在している複雑なケースでは、ツールの導入や専門家の支援を含め、数ヶ月以上かかることも珍しくありません。
名寄せを外注(アウトソーシング)することはできますか?
はい、名寄せ作業を専門の業者に外注(アウトソーシング)することは可能です。
データクレンジングや名寄せのサービスを提供する企業は多数存在します。
社内に専門知識を持つ人材や作業リソースがない場合に有効な選択肢となります。
ただし、個人情報を外部に渡すことになるため、委託先のセキュリティ体制や実績を十分に確認することが重要です。
どのようなタイミングで名寄せを実施するのが効果的ですか?
名寄せは、CRMやSFAといった新しいシステムを導入するタイミングや、複数の事業部で管理していた顧客データを統合する際に行うのが非常に効果的です。
また、「営業リストの精度を改善したい」「正確なデータ分析基盤を構築したい」など、データ活用に関する具体的な課題意識が高まった時も、実施に適したタイミングと言えます。
まとめ
名寄せは、単なるデータの整理作業ではなく、企業の営業力やマーケティング力を底上げするための重要な基盤作りです。正確なデータ管理は、顧客への二重アプローチといったミスを防ぎ、信頼関係の維持に直結します。
さらに効率的かつ高精度な名寄せを実現したい場合には、営業支援ツール「ホットプロファイル」の活用が有効です。名刺をスキャンするだけで、独自のデータベースと照合し、企業属性の付与や重複データの自動統合をスムーズに行います。
手作業による工数を大幅に削減しながら、常に最新でクリーンな顧客マスターを維持できるため、データドリブンな営業活動を強力に推進します。
関連記事:顧客リストとは?作り方・必須項目・Excel管理の限界と最適な運用方法を徹底解説

投稿者ハンモック編集部
現場での経験やリサーチをもとに、読者にとって役立つ情報をわかりやすくお届けしています。実務で得た知見をもとに、新たな気づきにつながる情報発信を心がけています。






























