OCRの仕組みとは?AIとの違いや文字認識の基本をわかりやすく解説
- INDEX
-

OCRを導入して業務効率化を図りたいと考えているものの、どのような仕組みで文字を読み取るのか、AI搭載モデルとは何が違うのか、その基本がわからずお困りではないでしょうか。
OCRとは、画像データのなかから文字を見つけ出し、編集可能なテキストデータに変換する技術のことです。
この技術の背景にある仕組みを理解することは、自社の課題解決に最適なツールを選ぶうえで重要となります。
OCR(光学文字認識)の基本をわかりやすく解説
OCRとは「Optical Character Recognition」の略称で、日本語では「光学文字認識」と訳されます。
スキャナやカメラなどで作成した画像ファイルに含まれる文字を認識し、コンピューターで利用できるテキストデータに変換するソフトウェア技術を指します。
従来、紙の書類に書かれた情報をシステムに入力するには、人間が目視で確認しながら手作業で打ち込む必要がありました。
OCR技術を活用することで、この入力作業を自動化し、業務の手間を大幅に削減できます。
わかりやすく言えば、紙の文字情報をデジタル情報に変換する橋渡しの役割を担う技術です。
この仕組みは、ペーパーレス化やDX(デジタルトランスフォーメーション)推進の基盤としても注目されています。
OCRが文字をテキストデータに変換する4つのステップ
OCRによる文字の読み取りは、単一の処理で完結するわけではありません。
一般的に、紙の書類がテキストデータに変換されるまでには、大きく分けて4つのプロセスが存在します。
まず書類を画像として取り込み、次に認識しやすいように画像の品質を整えます。
その後、画像の中から文字の部分を特定し、最終的にデータベースと照合して文字を決定するという流れです。
この一連のステップを経ることで、画像データ内の文字が編集可能なテキスト情報へと変わります。
ここでは、それぞれのステップでどのような手法が用いられているかを具体的に解説します。
ステップ1:スキャナで紙の書類を画像データとして取り込む
最初のステップは、文字認識の対象となる紙の書類をデジタル画像に変換する作業です。
スキャナや複合機、スマートフォンやデジタルカメラなどを用いて書類を撮影し、画像データとして取り込みます。
このとき、生成されるファイルの形式はJPEG、PNG、TIFF、PDFなどが一般的です。
この段階では、書類は単なる「絵」や「写真」として扱われており、ファイル内部にテキスト情報は含まれていません。
後続の処理で正確に文字を認識するためには、この最初のステップでできるだけ鮮明で歪みのない、高品質な画像データを用意することが重要になります。
ステップ2:画像の傾き補正やノイズ除去を行う(前処理)
画像データを取り込んだ後、文字認識の精度を高めるための「前処理」を行います。
スキャンした際に発生した画像の傾きを自動で水平に補正する機能(傾き補正)や、紙の地色や汚れ、裏写りといった不要な情報を取り除く「ノイズ除去」がその代表例です。
また、画像を白と黒の2色に変換して文字と背景のコントラストを明確にする「二値化」という処理も行われます。
これらの前処理によって、OCRが文字の形状をより正確に抽出しやすくなります。
近年のOCRツールは、こうした補正機能を標準で搭載しているものが多く、読み取り精度を安定させるうえで欠かせない工程です。
ステップ3:画像から文字の領域を特定し特徴を抽出する
前処理でクリーンになった画像から、どの部分が文字で、どの部分が背景や図表なのかを識別する「レイアウト解析」が行われます。
これにより、文章のブロックや個々の行が特定されます。
続いて、特定された行の中から1文字ずつを切り出す「文字切り出し」という処理に進みます。
切り出された個々の文字画像から、その文字がどのような形をしているのか、その特徴を抽出します。
例えば、線の交わる位置、線の端点の数、空白部分 spacing の形状、曲線の曲がり具合といった幾何学的な情報がデータとして取り出され、これが次のステップで文字を特定するための重要な手がかりとなります。
ステップ4:抽出した特徴をデータベースと照合し文字を認識・出力する
最後のステップでは、ステップ3で抽出した文字の特徴を、OCRソフトウェアが内部に保持している文字パターンのデータベースと照合します。
このデータベースには、ひらがな、カタカナ、漢字、アルファベット、数字など、様々な文字のお手本となる特徴データが事前に登録されています。
OCRは、読み取った文字の特徴とデータベース内の特徴を一つひとつ比較し、最も一致度が高いと判断された文字を、認識結果として採用します。
この一連のOCR読み取りプロセスを経て、最終的に画像データ内の文字がテキストデータとして出力され、ユーザーが編集やコピー&ペーストできる状態になります。
従来のOCRとAI-OCRの決定的な違い
OCRには、大きく分けて「従来型OCR」と「AI-OCR」の2つの種類が存在します。
両者の最も大きな違いは、文字を認識するための基本的な仕組みにあります。
従来型OCRが、あらかじめ定められたルールに基づいて文字を識別する「ルールベース」の手法であるのに対し、AI-OCRは人工知能(AI)、特にディープラーニング(深層学習)を活用して文字の特徴を自ら学習する「学習ベース」の手法を採用しています。
この根本的なアプローチの違いが、読み取り精度や対応できる帳票の種類に大きな差を生み出しています。
【従来型】登録された文字パターンと照合して認識する
従来のOCRは「パターンマッチング方式」と呼ばれる手法が主流です。
これは、ソフトウェアのデータベースに「あ」や「B」といった文字の形をフォントごとにパターンとして登録しておき、読み取った画像から切り出した文字と、この登録済みパターンを比較して、最も形状が似ているものを認識結果とする仕組みです。
代表的なオープンソースOCRエンジンであるTesseractも、元々はこの方式で開発されました。
この手法は、活字のように定まった形の文字(定型文字)の認識には強い一方で、データベースに登録されていないフォントや、書き手によって形が大きく異なる手書き文字の認識は非常に苦手としていました。
【AI-OCR】ディープラーニングで文字の特徴を自ら学習して認識する
AI-OCRは、人間の脳神経回路の仕組みを模したディープラーニング(深層学習)という技術を活用しています。
大量の文字データをAIに読み込ませることで、AIが自ら文字の持つ細かな特徴(例えば「木」という漢字は縦棒と横棒、払いで構成される、など)を自動で学習します。
この学習能力により、多少崩れた手書き文字や、かすれた印字、多様なフォントであっても、AIが文脈や前後の文字との関連性を考慮しながら高い精度で文字を特定できます。
これにより、従来は困難だった手書きのアンケート用紙や、企業ごとにフォーマットが異なる請求書(非定型帳票)の読み取りも可能になりました。
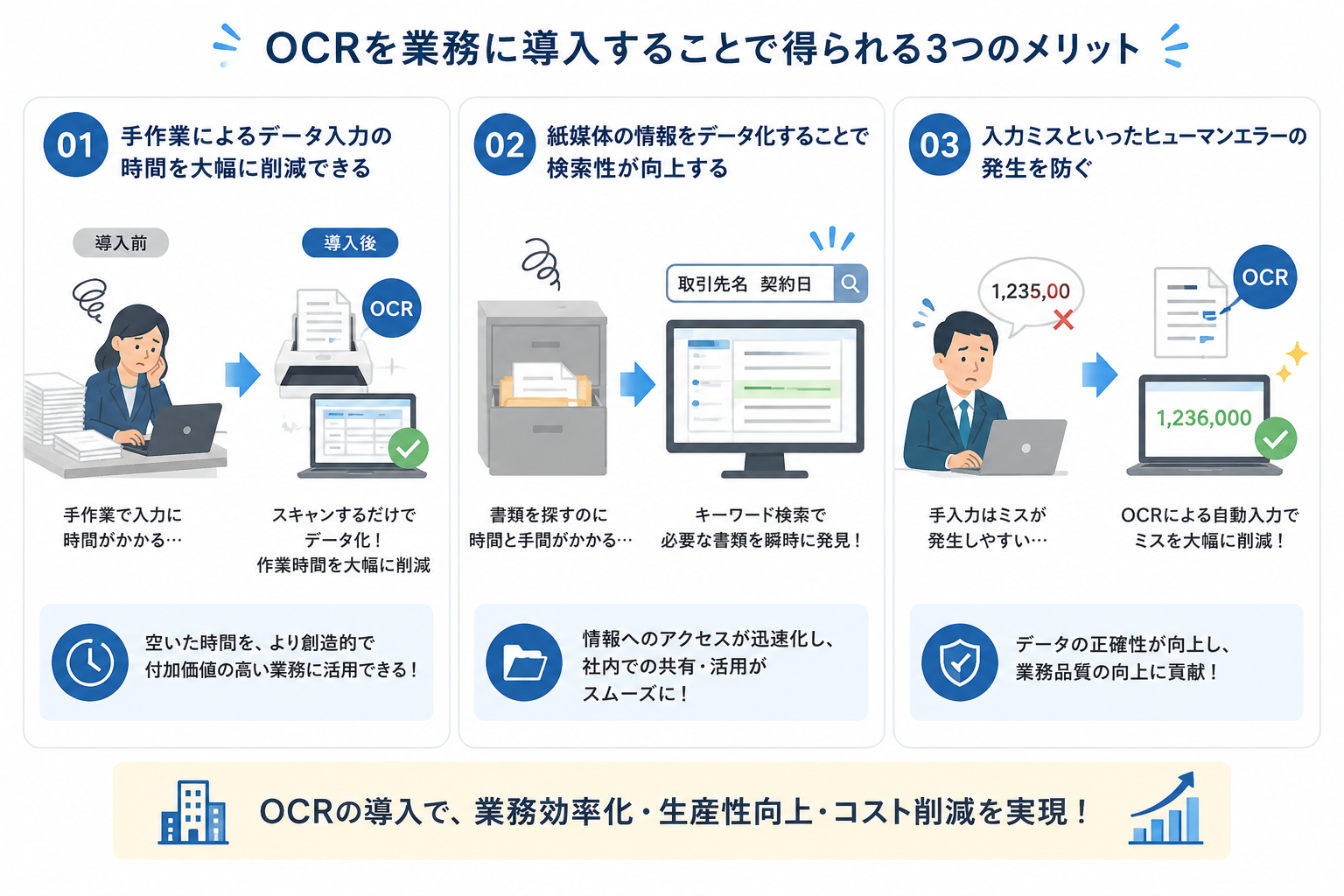
OCRを業務に導入することで得られる3つのメリット
OCRを使うことによって、企業は様々な恩恵を受けることができます。
これまで手作業に頼っていた紙ベースの業務を自動化することで、単に作業時間が短縮されるだけでなく、人的リソースの再配置やデータの活用促進にもつながります。
特に、大量の書類を扱う経理部門や総務部門、顧客情報を管理する営業部門などでは、その効果を大きく実感できるでしょう。
ここでは、OCR導入がもたらす代表的な3つのメリットについて具体的に解説します。
手作業によるデータ入力の時間を大幅に削減できる
OCRを導入する最大のメリットは、データ入力にかかる工数を劇的に削減できる点です。
例えば、毎月大量に届く請求書や納品書の内容を会計システムや販売管理システムに入力する作業は、多くの企業で大きな負担となっています。
OCRを活用すれば、これらの書類をスキャンするだけで必要な情報が自動でテキストデータ化されるため、担当者がキーボードで一つひとつ打ち込む手間が不要になります。
データ入力の時間を短縮できた、あるいは他の業務に時間を割けるようになった、とされる事例は数多く報告されており、従業員はより創造的で付加価値の高い業務に集中できるようになります。
紙媒体の情報をデータ化することで検索性が向上する
紙の書類は、ファイリングしてキャビネットに保管するのが一般的ですが、過去の特定の書類を探し出す際には多くの時間と労力がかかります。
OCRは、これらの紙媒体に記載された情報をテキストデータとして保存するため、情報の検索性が飛躍的に向上します。
例えば、「取引先名」や「契約日」といったキーワードで検索すれば、該当する書類データを瞬時に見つけ出すことが可能です。
これにより、必要な情報へのアクセスが迅速化し、業務のスピードアップが図れます。
また、データ化された情報は社内での共有も容易になり、組織全体の情報活用を促進します。
入力ミスといったヒューマンエラーの発生を防ぐ
人間が手作業でデータを入力する場合、どれだけ注意を払っていても打ち間違いや読み間違いといったヒューマンエラーを完全になくすことは困難です。
特に、桁数の多い金額や複雑な製品コードなどの入力では、ミスが発生しやすくなります。
OCRによる自動入力は、このような人為的なミスを大幅に減らし、データの正確性を高める効果があります。
もちろんOCRの認識精度も100%ではありませんが、目視による確認作業と組み合わせることで、手入力のみの場合と比較して格段にエラー率を低減させることができ、業務品質の向上に直接的に貢献します。
OCR導入前に知っておきたいデメリットと注意点
OCRは業務効率化に大きく貢献する便利なツールですが、万能というわけではありません。
その特性や限界を理解せずに導入すると、「期待したほどの効果が得られなかった」ということにもなりかねません。
導入を成功させるためには、OCRが苦手とすることや、運用上注意すべき点を事前に把握し、それらを前提とした業務フローを設計することが重要です。
ここでは、OCRを導入する前に知っておくべきデメリットや注意点について解説します。
手書き文字や複雑なレイアウトは誤認識する可能性がある
AI-OCRの登場により手書き文字の認識精度は飛躍的に向上しましたが、それでも癖の強い文字や続け字、殴り書きなどは正しく認識できない場合があります。
また、書類のレイアウトも精度に大きく影響します。
例えば、枠線に文字が重なっている、複数の項目が狭いスペースに密集している、背景に色や模様が入っているといった複雑なレイアウトの帳票は、文字とそれ以外の要素の切り分けが難しくなり、誤認識の原因となります。
特に定型帳票に特化した従来型のOCRでは、少しでもフォーマットが異なると正確に読み取れないケースが多く見られます。
100%の精度ではないため目視での確認作業が必要になる
OCR技術がいかに進化しても、現状では100%の精度を保証することはできません。
読み取り条件や原稿の状態によっては、文字を誤って認識したり、読み取れなかったりする箇所が必ず発生します。
そのため、OCRでデータ化した後は、その結果が正しいかどうかを人間が目視で確認し、必要に応じて修正する作業が不可欠です。
この確認・修正プロセスを怠ると、誤ったデータが後続のシステムに登録されてしまい、かえって業務に混乱を招く恐れがあります。
「OCRを導入すれば全ての作業が全自動化される」と考えるのではなく、あくまで「人間の作業を補助するツール」と位置づけ、確認作業を組み込んだ運用体制を構築することが重要です。
OCRの文字認識精度を最大限に高める3つのポイント
OCRの読み取り精度は、使用するソフトウェアの性能だけでなく、読み取らせる画像の品質にも大きく左右されます。
つまり、OCRが能力を最大限に発揮できるように、利用者が少し工夫するだけで、認識率を大きく向上させることが可能です。
これから紹介する3つのポイントは、いずれも基本的なことですが、これらを意識するだけで誤認識を減らし、後工程での修正作業の手間を削減できます。
導入効果を高めるためにも、ぜひ実践してみてください。
関連記事:OCRのメリット・デメリットとは?AI-OCRとの違いや活用事例を解説
スキャンする際は高解像度に設定し鮮明な画像を用意する
OCRの精度は、元となる画像の解像度に大きく依存します。
解像度が低いと、文字のエッジがぼやけたり、線が潰れて見えたりするため、OCRが文字の正しい特徴を捉えきれなくなります。
一般的に、OCR処理には300dpi以上の解像度が推奨されています。
スキャナや複合機で書類を取り込む際には、スキャン設定を確認し、少なくとも300dpi以上の解像度を選択するようにしましょう。
高解像度でスキャンすることで、文字がクリアになり、細部まで正確に認識されやすくなります。
文字のかすれや画像の歪みを事前に補正しておく
原稿の印字がかすれていたり、スキャン時に書類が傾いて歪んだ画像になったりすると、それらが直接誤認識の原因となります。
多くのOCRソフトウェアには、画像の傾きを自動で補正する機能や、画像の明るさ・コントラストを調整して文字を鮮明にする機能が備わっています。
これらの前処理機能を積極的に活用しましょう。
また、スキャンする際には、原稿をまっすぐにセットし、ガラス面にゴミや汚れがないかを確認することも重要です。
一手間加えることで、OCRが読み取りやすいクリーンな画像を用意できます。
背景がシンプルで文字がはっきりした原稿を使用する
OCRは、文字と背景を明確に区別することで性能を発揮します。
理想的な原稿は、白い紙に黒い文字ではっきりと印字されているものです。
背景に色が付いていたり、社名のロゴや模様(地紋)が印刷されていたりすると、OCRがそれらを文字の一部として誤認識してしまう可能性があります。
可能であれば、OCRで読み取ることを前提とした帳票設計(シンプルなレイアウト、背景なしなど)を行うのが最も効果的です。
既存の書類を読み取る場合でも、コントラストがはっきりした状態の良い原稿を選ぶことで、認識精度を高めることができます。
OCR技術の具体的な活用シーンを紹介
OCR技術は、特定の業界や部門に限らず、紙の書類を扱うあらゆる業務でその能力を発揮します。
定型的なデータ入力作業を自動化することで、業務の効率化や迅速化、ヒューマンエラーの削減に貢献し、従業員をより付加価値の高い仕事へとシフトさせます。
ここでは、多くの企業で共通して見られる課題を解決する、OCRの具体的な活用シーンを3つ取り上げて紹介します。
自社の業務に当てはまるものがないか、確認してみてください。
請求書や領収書の処理を自動化する
経理部門では、毎月多くの取引先から送られてくる請求書や、従業員が経費精算のために提出する領収書の処理に多くの時間を費やしています。
OCRを活用すれば、これらの書類に記載されている「発行日」「取引先名」「品目」「金額」といった情報を自動で読み取り、会計システムにデータとして取り込むことが可能です。
これにより、手入力にかかる時間が大幅に削減されるだけでなく、入力ミスも防げるため、月次決算の早期化や業務品質の向上につながります。
名刺情報を読み取り顧客リストを作成する
営業担当者が日々交換する大量の名刺は、重要な顧客情報ですが、その管理は属人化しがちです。
OCR機能を搭載した名刺管理アプリやソフトウェアを使えば、スマートフォンで名刺を撮影するだけで、社名、部署、役職、氏名、連絡先などの情報が自動でテキストデータ化されます。
データ化された情報は、顧客管理システム(CRM)や営業支援システム(SFA)に簡単に登録でき、組織全体で顧客情報を一元管理・共有することが可能になります。
これにより、迅速なアプローチや効率的な営業活動が実現します。
アンケート用紙の回答を自動で集計する
イベントやセミナーで収集した紙のアンケート用紙は、集計作業に多大な労力がかかります。
特に、自由記述欄のテキスト化は手間のかかる作業です。
OCRを導入すれば、選択式のチェック項目はもちろん、手書きの自由記述回答もまとめてスキャンし、自動でデータ化できます。
これにより、集計作業が大幅に効率化され、結果の分析にいち早く取り掛かることが可能になります。
顧客の声を迅速に製品開発やサービス改善に活かすための強力なツールとなります。
ocr 仕組みに関するよくある質問
ここでは、OCRの仕組みや導入に関して頻繁に寄せられる質問とその回答をまとめました。
OCRが苦手な文字の種類や、他のツールとの連携による効果、スマートフォンのアプリの性能など、より実践的な内容に触れていきます。
OCRで読み取れない文字はありますか?
はい、あります。
著しく崩れた手書き文字や、手書きの続け字、デザイン性の高い装飾的なフォントは、正しく認識できない場合があります。
また、印字が極端にかすれている、汚れで文字が判読不能、背景の模様と文字が重なっているといったケースも読み取りが困難です。
AI-OCRの進化により認識能力は向上し続けていますが、100%の精度ではないのが現状です。
OCRとRPAを組み合わせると何ができますか?
データ入力から後続処理まで、一連の定型業務を完全に自動化できます。
例えば、OCRで請求書から抽出したデータを、RPAが会計システムに自動で入力し、さらに処理完了のメールを担当者に送信するといった連携が可能です。
OCRが目の役割、RPAが手の役割を担うことで、人の手を介さない業務フローを構築し、生産性を飛躍的に向上させます。
スマートフォンアプリのOCRでも精度は高いですか?
はい、近年のアプリは非常に高精度です。
スマートフォンのカメラ性能の向上とAI技術の普及により、多くのアプリがAI-OCRエンジンを搭載しています。
そのため、レシートや名刺、書類などを撮影するだけで、手軽に高精度なテキスト化が可能です。
個人的な利用や小規模な業務であれば、専用スキャナや高価なソフトウェアを導入せずとも、スマートフォンアプリで十分に対応できるケースが増えています。
まとめ
OCRは、画像内の文字を識別しテキストデータに変換する技術であり、画像取り込み、前処理、文字領域の特定と特徴抽出、データベース照合という4つのステップで処理が実行されます。
従来型OCRは登録されたパターンと照合する仕組みですが、AI-OCRはディープラーニングによって自ら文字の特徴を学習するため、手書き文字や多様な帳票にも高い精度で対応可能です。
この技術を業務に導入することで、データ入力の工数削減、検索性の向上、ヒューマンエラーの防止といったメリットが得られます。
ただし、100パーセントの精度ではないため、目視による確認作業は依然として必要です。
OCRの仕組みと限界を正しく理解し、自社の課題解決に役立ててください。
もし、より高精度な文字認識と業務効率化を両立させたいとお考えであれば、弊社の「DX OCR」の活用が有効です。
最先端のAI技術を搭載した「DX OCR」なら、複雑な帳票もスムーズにデータ化し、貴社のDX推進を強力にバックアップします。

投稿者ハンモック編集部
現場での経験やリサーチをもとに、読者にとって役立つ情報をわかりやすくお届けしています。実務で得た知見をもとに、新たな気づきにつながる情報発信を心がけています。